
Производительность
Начнём с того, что сегодня (на данный момент стабильная ветка — 8.2, актуальная версия — 8.2.5) PostgreSQL успешно тягается в плане производительности не только с OpenSource-альтернативами, но и с ведущими коммерческими СУБД. Такими как Oracle. Это уже не пустой звук — взгляните на результаты тестирования, проведённого в компании Sun. Медленных слонов больше нет! Богатейший набор типов индексов, широчайшие возможности тюнинга системы, работа с очень большими объёмами и нагрузками, хороший выбор систем репликации и масштабирования — всё это «по зубам» современным слонам. Даже скорость разработки выгодно отличает Постгрес по сравнению с другими СУБД: каждый год мы неизменно получаем существенный шаг вперёд.
Что же нового в PostgreSQL версии 8.3 в плане производительности? Многие изменения нетривиальны. По словам координатора разработки PostgreSQL Брюса Момджана (Bruce Momjian), нанёсшего не так давно по приглашению компании «Постгресмен» визит в Москву, та работа по оптимизации производительности системы, которой заняты разработчики Постгреса в последние годы, является чрезвычайно сложной. Каждый шаг требует всё более и более существенных трудозатрат, занимает всё больше времени и сил разработчиков.
Одним из таких действительно нетривиальных изменений можно смело считать «фишку» под названием HOT (Heap Only Tuples). Это, пожалуй, одно из самых существенных изменений в плане производительности. Чтобы понять, в чём заключается данное изменение, необходимо вспомнить, что PostgreSQL реализует так называемую мультиверсионную модель разграничения доступа (MVCC, Multi-Version Concurrency Control).
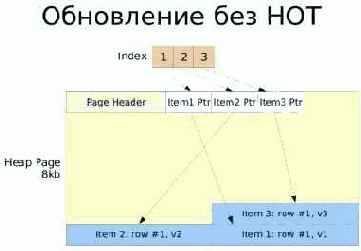

Суть HOT в следующем. Ранее, до реализации данного подхода, при обновлении строки в таблице каждая новая её версия приводила к появлению новых версий всех индексов, независимо от того, затрагивали ли данные изменения проиндексированные столбцы или нет (см. рис. «Обновление без HOT»). Теперь же, если новая версия строки попадает в ту же страницу памяти, что и предыдущая, и столбцы, по которым был создан индекс, не изменялись, индекс остаётся прежним. Но это ещё не всё. Если есть такая возможность, происходит «моментальное» повторное использование места в странице Heap. Что, естественно, сокращает объём работы, производимой при операции VACUUM. На рис. «HOT-обновление» схематически отображено, каким образом происходит теперь обновление строки.
Следующая новинка придётся по вкусу, прежде всего, большому количеству веб-разработчиков. Начиная с версии 8.3 любую транзакцию в PostgreSQL можно делать «асинхронной».
Это означает, что при выполнении операции фиксации транзакции (COMMIT) сервер PostgreSQL не будет ждать завершения дорогостоящей операции синхронизации журнала транзакций (WAL fsync). Другими словами, транзакция будет считаться успешно завершённой сразу же, как только все логические условия будут выполнены (проверены все необходимые ограничения целостности). Физически запись в журнал транзакций произойдёт через очень малый промежуток времени (как правило, для нормально функционирующих систем это максимум 200-1000 мс).За состояние транзакции (синхронная/асинхронная) отвечает переменная окружения synchronous_commit. Перейти в асинхронный режим просто: SET synchronous_commit TO OFF;
Стоит отметить, что асинхронные транзакции не являются альтернативой режиму работы сервера с отключенной операций fsync. Дело в том, что режим fsync=off может привести к получению несогласованного состояния базы (к примеру, в случае непредвиденного отказа оборудования или потери питания) и рекомендуется только в тех случаях, когда используется оборудование высокой надёжности (например, контроллер дисков с батарейкой). Использование же новой возможности никак не может привести к рассогласованию данных. Максимум, что возможно, это потеря небольшой порции данных (опять-таки, в случае жёсткого сбоя сервера — ошибки ОС, оборудования, сбой питания). Типичным примером для асинхронных транзакций может служить задача сохранения большого количества информации в таблицу-журнал (например, лог действий пользователя), когда потеря нескольких строк не является критичной. При этом все важные транзакции могут по-прежнему быть синхронными.

Ещё одно улучшение в области производительности относится к ситуациям, когда при выполнении запросов PostgreSQL последовательно просматривает таблицы (операция SeqScan). Если до версии 8.3 в таких случаях нередко возникали ситуации, когда разные процесса Постгреса одновременно делали одну и ту же работу — просматривали одну и ту же таблицу — то теперь, благодаря реализации Synchronized Scans («синронизованные просмотры»), в один и тот же момент времени для одной таблицы может проводиться не более одной операции просмотра. Достигается это следующим образом. Если в рамках какой-либо сессии требуется проведение SeqScan-а для некоторой таблицы, для которой уже выполняется SeqScan (для другой сессии), то произойдёт «прыжок на ходу» к результатам уже выполняющегося SeqScan-а. По завершении данного процесса, если это необходимо, будет осуществлён «добор» результатов с помощью ещё одного неполного SeqScan-а (см. рис).
Работа над уменьшением стресс-эффекта, производимого выполнением системой процессов checkpoint («контрольная точка») продолжается: теперь checkpoint-ы выполняются не сразу, а постепенно: процесс как бы «размазан» во времени. Отсюда и название данного изменения — checkpoint smoothing. Стоит отметить, что при штатном выключении сервера и проведениия «явной» операции checkpoint (команда CHECKPOINT) запись данных на диск по-прежнему будет производиться с максимально возможной скоростью.
В завершение разговора о производительности, приведём краткий перечень других изменений, призванных улучшить быстродействие систем, использующих PostgreSQL: